本篇文章给大家带来了关于Python的相关知识,其中主要介绍了机器学习、深度学习库总结,其中包含了大量的实例,下面一起来看一下,希望对大家有帮助。
|
本篇文章给大家带来了关于python的相关知识,其中主要介绍了机器学习、深度学习库总结,其中包含了大量的实例,下面一起来看一下,希望对大家有帮助。
推荐学习:python视频教程 前言目前,随着人工智能的大热,吸引了诸多行业对于人工智能的关注,同时也迎来了一波又一波的人工智能学习的热潮,虽然人工智能背后的原理并不能通过短短一文给予详细介绍,但是像所有学科一样,我们并不需要从头开始”造轮子“,可以通过使用丰富的人工智能框架来快速构建人工智能模型,从而入门人工智能的潮流。 人工智能指的是一系列使机器能够像人类一样处理信息的技术;机器学习是利用计算机编程从历史数据中学习,对新数据进行预测的过程;神经网络是基于生物大脑结构和特征的机器学习的计算机模型;深度学习是机器学习的一个子集,它处理大量的非结构化数据,如人类的语音、文本和图像。因此,这些概念在层次上是相互依存的,人工智能是最广泛的术语,而深度学习是最具体的:
为了大家能够对人工智能常用的
python常用机器学习及深度学习库介绍1、 Numpy
import numpy as npimport mathimport randomimport time
start = time.time()for i in range(10):
list_1 = list(range(1,10000))
for j in range(len(list_1)):
list_1[j] = math.sin(list_1[j])print("使用纯Python用时{}s".format(time.time()-start))start = time.time()for i in range(10):
list_1 = np.array(np.arange(1,10000))
list_1 = np.sin(list_1)print("使用Numpy用时{}s".format(time.time()-start))从如下运行结果,可以看到使用 使用纯Python用时0.017444372177124023s 使用Numpy用时0.001619577407836914s 2、 OpenCV
import numpy as npimport cv2 as cvfrom matplotlib import pyplot as plt
img = cv.imread('h89817032p0.png')kernel = np.ones((5,5),np.float32)/25dst = cv.filter2D(img,-1,kernel)blur_1 = cv.GaussianBlur(img,(5,5),0)blur_2 = cv.bilateralFilter(img,9,75,75)plt.figure(figsize=(10,10))plt.subplot(221),plt.imshow(img[:,:,::-1]),plt.title('Original')plt.xticks([]), plt.yticks([])plt.subplot(222),plt.imshow(dst[:,:,::-1]),plt.title('Averaging')plt.xticks([]), plt.yticks([])plt.subplot(223),plt.imshow(blur_1[:,:,::-1]),plt.title('Gaussian')plt.xticks([]), plt.yticks([])plt.subplot(224),plt.imshow(blur_1[:,:,::-1]),plt.title('Bilateral')plt.xticks([]), plt.yticks([])plt.show()
可以参考OpenCV图像处理基础(变换和去噪),了解更多 OpenCV 图像处理操作。 3、 Scikit-image
from skimage import data, color, iofrom skimage.transform import rescale, resize, downscale_local_mean
image = color.rgb2gray(io.imread('h89817032p0.png'))image_rescaled = rescale(image, 0.25, anti_aliasing=False)image_resized = resize(image, (image.shape[0] // 4, image.shape[1] // 4),
anti_aliasing=True)image_downscaled = downscale_local_mean(image, (4, 3))plt.figure(figsize=(20,20))plt.subplot(221),plt.imshow(image, cmap='gray'),plt.title('Original')plt.xticks([]), plt.yticks([])plt.subplot(222),plt.imshow(image_rescaled, cmap='gray'),plt.title('Rescaled')plt.xticks([]), plt.yticks([])plt.subplot(223),plt.imshow(image_resized, cmap='gray'),plt.title('Resized')plt.xticks([]), plt.yticks([])plt.subplot(224),plt.imshow(image_downscaled, cmap='gray'),plt.title('Downscaled')plt.xticks([]), plt.yticks([])plt.show()
4、 Python Imaging Library(PIL)
5、 Pillow使用 from PIL import Image, ImageDraw, ImageFont, ImageFilterimport random# 随机字母:def rndChar():
return chr(random.randint(65, 90))# 随机颜色1:def rndColor():
return (random.randint(64, 255), random.randint(64, 255), random.randint(64, 255))# 随机颜色2:def rndColor2():
return (random.randint(32, 127), random.randint(32, 127), random.randint(32, 127))# 240 x 60:width = 60 * 6height = 60 * 6image = Image.new('RGB', (width, height), (255, 255, 255))# 创建Font对象:font = ImageFont.truetype('/usr/share/fonts/wps-office/simhei.ttf', 60)# 创建Draw对象:draw = ImageDraw.Draw(image)# 填充每个像素:for x in range(width):
for y in range(height):
draw.point((x, y), fill=rndColor())# 输出文字:for t in range(6):
draw.text((60 * t + 10, 150), rndChar(), font=font, fill=rndColor2())# 模糊:image = image.filter(ImageFilter.BLUR)image.save('code.jpg', 'jpeg')
6、 SimpleCV
from SimpleCV import Image, Color, Display# load an image from imgurimg = Image('http://i.imgur.com/lfAeZ4n.png')# use a keypoint detector to find areas of interestfeats = img.findKeypoints()# draw the list of keypointsfeats.draw(color=Color.RED)# show the resulting image. img.show()# apply the stuff we found to the image.output = img.applyLayers()# save the results.output.save('juniperfeats.png')会报如下错误,因此不建议在 SyntaxError: Missing parentheses in call to 'print'. Did you mean print('unit test')?7、 Mahotas
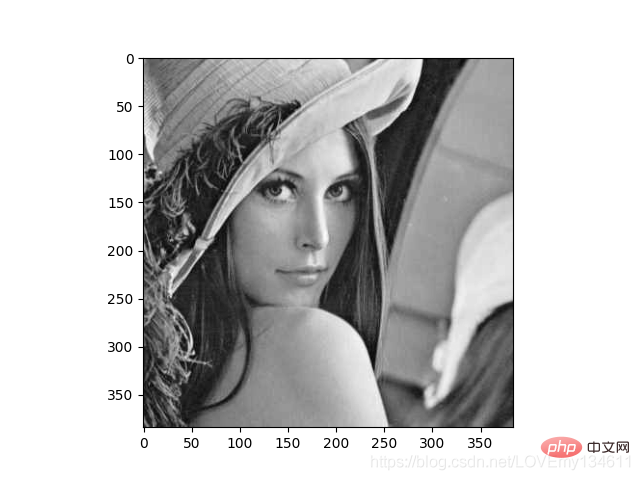
import numpy as npimport mahotasimport mahotas.demosfrom mahotas.thresholding import soft_thresholdfrom matplotlib import pyplot as pltfrom os import path
f = mahotas.demos.load('lena', as_grey=True)f = f[128:,128:]plt.gray()# Show the data:print("Fraction of zeros in original image: {0}".format(np.mean(f==0)))plt.imshow(f)plt.show()
8、 Ilastik
9、 Scikit-learn
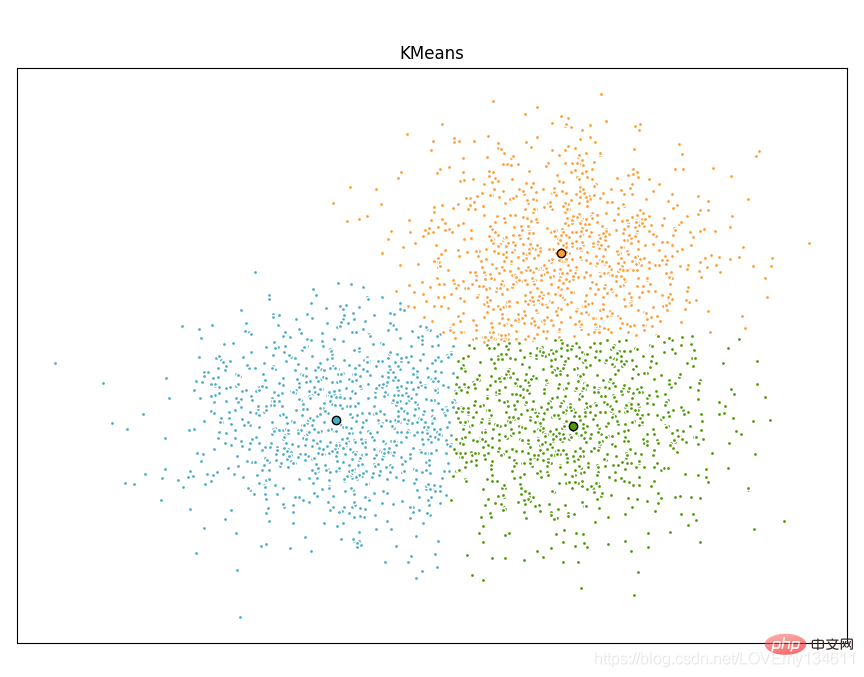
import timeimport numpy as npimport matplotlib.pyplot as pltfrom sklearn.cluster import MiniBatchKMeans, KMeansfrom sklearn.metrics.pairwise import pairwise_distances_argminfrom sklearn.datasets import make_blobs# Generate sample datanp.random.seed(0)batch_size = 45centers = [[1, 1], [-1, -1], [1, -1]]n_clusters = len(centers)X, labels_true = make_blobs(n_samples=3000, centers=centers, cluster_std=0.7)# Compute clustering with Meansk_means = KMeans(init='k-means++', n_clusters=3, n_init=10)t0 = time.time()k_means.fit(X)t_batch = time.time() - t0# Compute clustering with MiniBatchKMeansmbk = MiniBatchKMeans(init='k-means++', n_clusters=3, batch_size=batch_size,
n_init=10, max_no_improvement=10, verbose=0)t0 = time.time()mbk.fit(X)t_mini_batch = time.time() - t0# Plot resultfig = plt.figure(figsize=(8, 3))fig.subplots_adjust(left=0.02, right=0.98, bottom=0.05, top=0.9)colors = ['#4EACC5', '#FF9C34', '#4E9A06']# We want to have the same colors for the same cluster from the# MiniBatchKMeans and the KMeans algorithm. Let's pair the cluster centers per# closest one.k_means_cluster_centers = k_means.cluster_centers_
order = pairwise_distances_argmin(k_means.cluster_centers_,
mbk.cluster_centers_)mbk_means_cluster_centers = mbk.cluster_centers_[order]k_means_labels = pairwise_distances_argmin(X, k_means_cluster_centers)mbk_means_labels = pairwise_distances_argmin(X, mbk_means_cluster_centers)# KMeansfor k, col in zip(range(n_clusters), colors):
my_members = k_means_labels == k
cluster_center = k_means_cluster_centers[k]
plt.plot(X[my_members, 0], X[my_members, 1], 'w',
markerfacecolor=col, marker='.')
plt.plot(cluster_center[0], cluster_center[1], 'o', markerfacecolor=col,
markeredgecolor='k', markersize=6)plt.title('KMeans')plt.xticks(())plt.yticks(())plt.show()
10、 SciPy
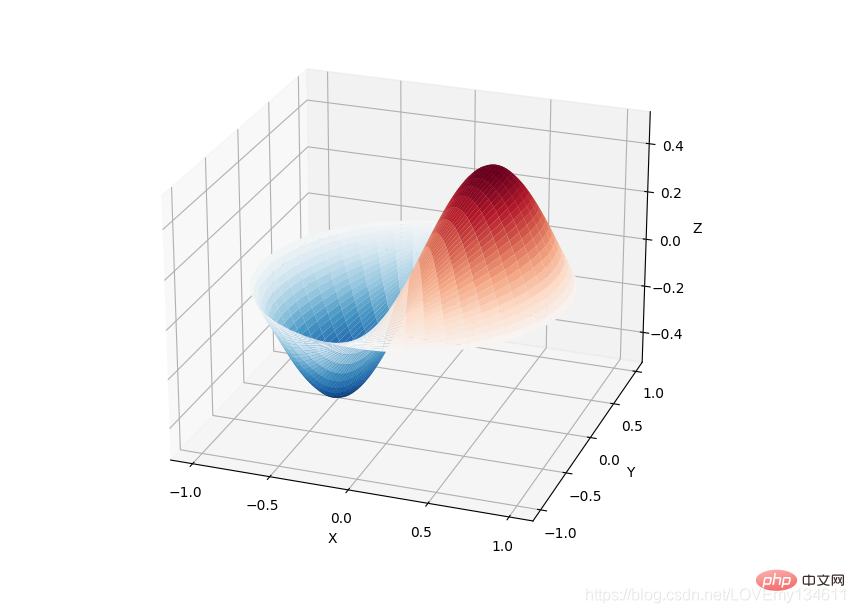
from scipy import specialimport matplotlib.pyplot as pltimport numpy as npdef drumhead_height(n, k, distance, angle, t):
kth_zero = special.jn_zeros(n, k)[-1]
return np.cos(t) * np.cos(n*angle) * special.jn(n, distance*kth_zero)theta = np.r_[0:2*np.pi:50j]radius = np.r_[0:1:50j]x = np.array([r * np.cos(theta) for r in radius])y = np.array([r * np.sin(theta) for r in radius])z = np.array([drumhead_height(1, 1, r, theta, 0.5) for r in radius])fig = plt.figure()ax = fig.add_axes(rect=(0, 0.05, 0.95, 0.95), projection='3d')ax.plot_surface(x, y, z, rstride=1, cstride=1, cmap='RdBu_r', vmin=-0.5, vmax=0.5)ax.set_xlabel('X')ax.set_ylabel('Y')ax.set_xticks(np.arange(-1, 1.1, 0.5))ax.set_yticks(np.arange(-1, 1.1, 0.5))ax.set_zlabel('Z')plt.show()
11、 NLTK
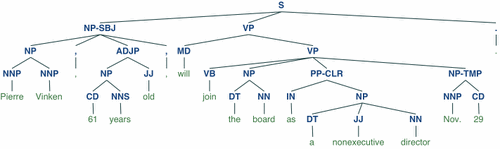
import nltkfrom nltk.corpus import treebank# 首次使用需要下载nltk.download('punkt')nltk.download('averaged_perceptron_tagger')nltk.download('maxent_ne_chunker')nltk.download('words')nltk.download('treebank')sentence = """At eight o'clock on Thursday morning Arthur didn't feel very good."""# Tokenizetokens = nltk.word_tokenize(sentence)tagged = nltk.pos_tag(tokens)# Identify named entitiesentities = nltk.chunk.ne_chunk(tagged)# Display a parse treet = treebank.parsed_sents('wsj_0001.mrg')[0]t.draw()
12、 spaCy
import spacy
texts = [
"Net income was $9.4 million compared to the prior year of $2.7 million.",
"Revenue exceeded twelve billion dollars, with a loss of $1b.",
]
nlp = spacy.load("en_core_web_sm")
for doc in nlp.pipe(texts, disable=["tok2vec", "tagger", "parser", "attribute_ruler", "lemmatizer"]):
# Do something with the doc here
print([(ent.text, ent.label_) for ent in doc.ents])
[('$9.4 million', 'MONEY'), ('the prior year', 'DATE'), ('$2.7 million', 'MONEY')][('twelve billion dollars', 'MONEY'), ('1b', 'MONEY')]13、 LibROSA
# Beat tracking exampleimport librosa# 1. Get the file path to an included audio examplefilename = librosa.example('nutcracker')# 2. Load the audio as a waveform `y`# Store the sampling rate as `sr`y, sr = librosa.load(filename)# 3. Run the default beat trackertempo, beat_frames = librosa.beat.beat_track(y=y, sr=sr)print('Estimated tempo: {:.2f} beats per minute'.format(tempo))# 4. Convert the frame indices of beat events into timestampsbeat_times = librosa.frames_to_time(beat_frames, sr=sr)14、 Pandas
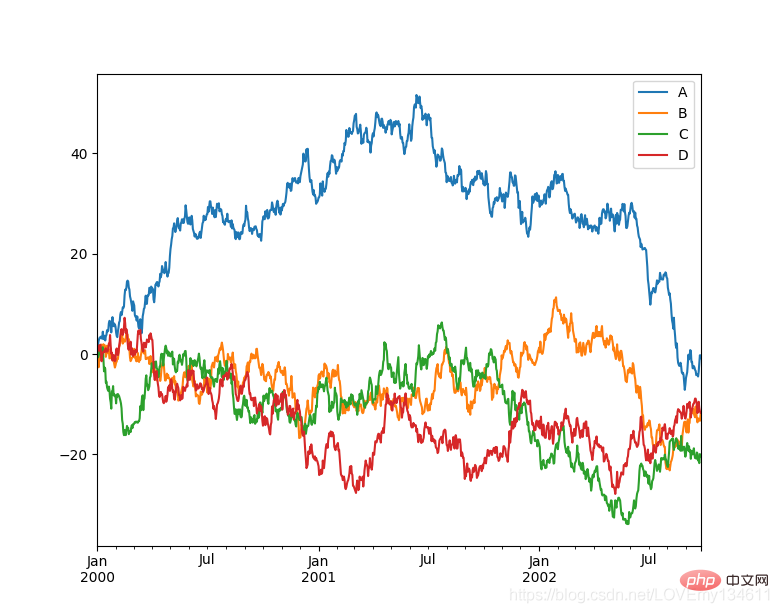
import matplotlib.pyplot as pltimport pandas as pdimport numpy as np
ts = pd.Series(np.random.randn(1000), index=pd.date_range("1/1/2000", periods=1000))ts = ts.cumsum()df = pd.DataFrame(np.random.randn(1000, 4), index=ts.index, columns=list("ABCD"))df = df.cumsum()df.plot()plt.show()
15、 Matplotlib
# plot_multi_curve.pyimport numpy as npimport matplotlib.pyplot as plt x = np.linspace(0.1, 2 * np.pi, 100)y_1 = x y_2 = np.square(x)y_3 = np.log(x)y_4 = np.sin(x)plt.plot(x,y_1)plt.plot(x,y_2)plt.plot(x,y_3)plt.plot(x,y_4)plt.show()
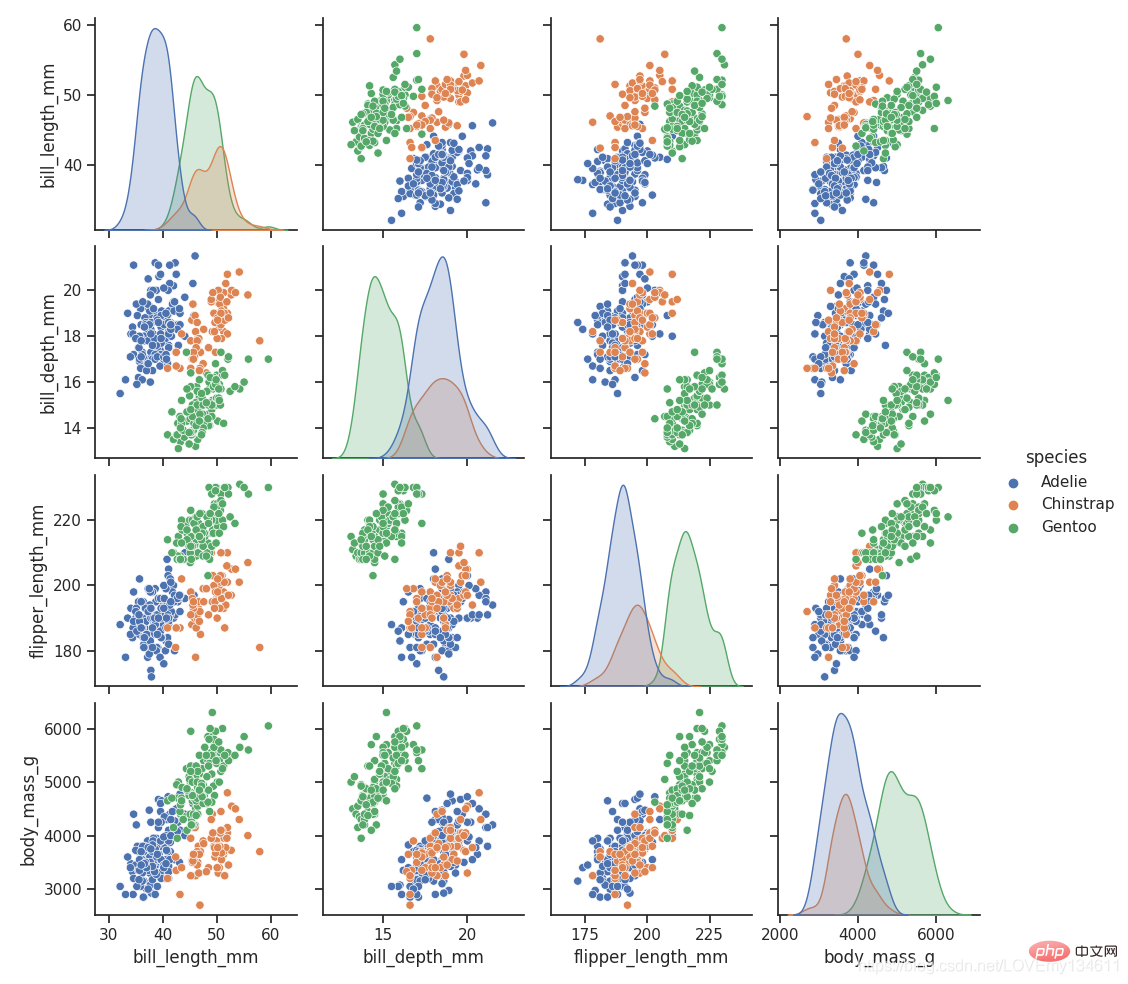
16、 Seaborn
import seaborn as snsimport matplotlib.pyplot as plt
sns.set_theme(style="ticks")df = sns.load_dataset("penguins")sns.pairplot(df, hue="species")plt.show()
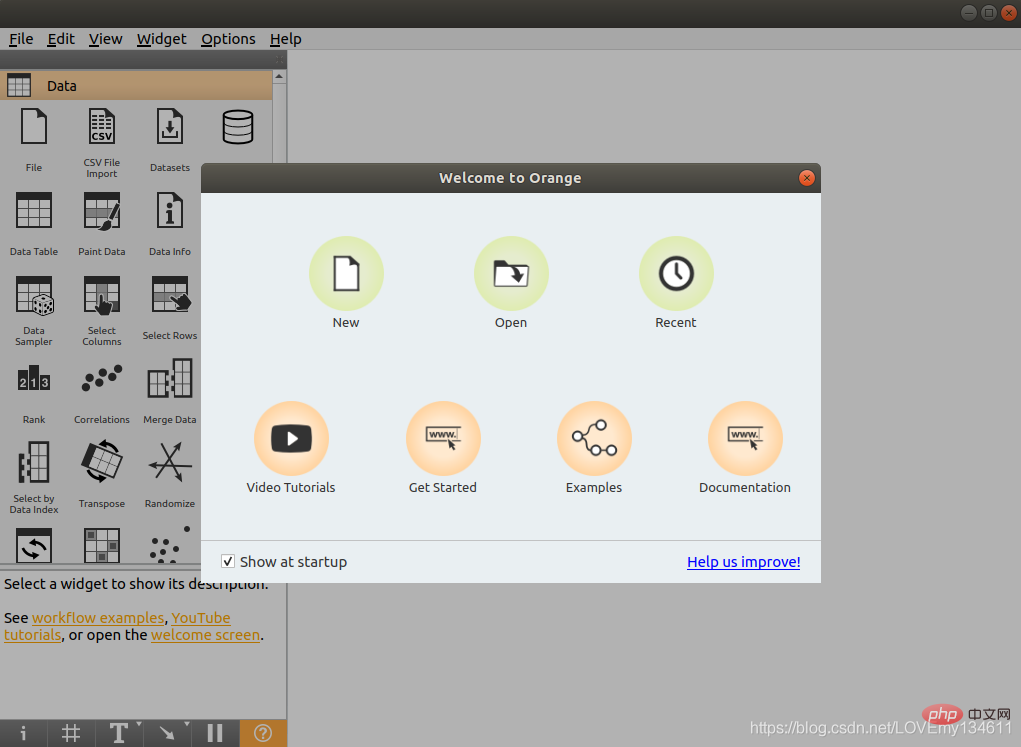
17、 Orange
$ pip install orange3 安装完成后,在命令行输入 $ orange-canvas 启动完成后,即可看到
18、 PyBrain
from pybrain.structure import FeedForwardNetwork n = FeedForwardNetwork() 接下来,构建输入、隐藏和输出层: from pybrain.structure import LinearLayer, SigmoidLayer inLayer = LinearLayer(2)hiddenLayer = SigmoidLayer(3)outLayer = LinearLayer(1) 为了使用所构建的层,必须将它们添加到网络中: n.addInputModule(inLayer)n.addModule(hiddenLayer)n.addOutputModule(outLayer) 可以添加多个输入和输出模块。为了向前计算和反向误差传播,网络必须知道哪些层是输入、哪些层是输出。 from pybrain.structure import FullConnection in_to_hidden = FullConnection(inLayer, hiddenLayer)hidden_to_out = FullConnection(hiddenLayer, outLayer) 与层一样,我们必须明确地将它们添加到网络中: n.addConnection(in_to_hidden)n.addConnection(hidden_to_out) 所有元素现在都已准备就位,最后,我们需要调用.sortModules()方法使MLP可用: n.sortModules() 这个调用会执行一些内部初始化,这在使用网络之前是必要的。 19、 Milk
import numpy as npimport milk features = np.random.rand(100,10)labels = np.zeros(100)features[50:] += .5labels[50:] = 1learner = milk.defaultclassifier()model = learner.train(features, labels)# Now you can use the model on new examples:example = np.random.rand(10)print(model.apply(example))example2 = np.random.rand(10)example2 += .5print(model.apply(example2)) 20、 TensorFlow
import tensorflow as tffrom tensorflow.keras import datasets, layers, models# 数据加载(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()# 数据预处理train_images, test_images = train_images / 255.0, test_images / 255.0# 模型构建model = models.Sequential()model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)))model.add(layers.MaxPooling2D((2, 2)))model.add(layers.Conv2D(64, (3, 3), activation='relu'))model.add(layers.MaxPooling2D((2, 2)))model.add(layers.Conv2D(64, (3, 3), activation='relu'))model.add(layers.Flatten())model.add(layers.Dense(64, activation='relu'))model.add(layers.Dense(10))# 模型编译与训练model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])history = model.fit(train_images, train_labels, epochs=10,
validation_data=(test_images, test_labels))想要了解更多Tensorflow2.x的示例,可以参考专栏 Tensorflow. 21、 PyTorch
# 导入库import torchfrom torch import nnfrom torch.utils.data import DataLoaderfrom torchvision import datasetsfrom torchvision.transforms import ToTensor, Lambda, Composeimport matplotlib.pyplot as plt# 模型构建device = "cuda" if torch.cuda.is_available() else "cpu"print("Using {} device".format(device))# Define modelclass NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
nn.ReLU()
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
model = NeuralNetwork().to(device)# 损失函数和优化器loss_fn = nn.CrossEntropyLoss()optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)# 模型训练def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
for batch, (X, y) in enumerate(dataloader):
X, y = X.to(device), y.to(device)
# Compute prediction error
pred = model(X)
loss = loss_fn(pred, y)
# Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch % 100 == 0:
loss, current = loss.item(), batch * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")22、 Theano
import theanoimport theano.tensor as T
x = T.dvector('x')y = x ** 2J, updates = theano.scan(lambda i, y,x : T.grad(y[i], x), sequences=T.arange(y.shape[0]), non_sequences=[y,x])f = theano.function([x], J, updates=updates)f([4, 4])23、 Keras
from keras.models import Sequentialfrom keras.layers import Dense# 模型构建model = Sequential()model.add(Dense(units=64, activation='relu', input_dim=100))model.add(Dense(units=10, activation='softmax'))# 模型编译与训练model.compile(loss='categorical_crossentropy',
optimizer='sgd',
metrics=['accuracy'])model.fit(x_train, y_train, epochs=5, batch_size=32)24、 Caffe在 Caffe2 官方网站上,这样说道: 25、 MXNet
import mxnet as mxfrom mxnet import gluonfrom mxnet.gluon import nnfrom mxnet import autograd as agimport mxnet.ndarray as F# 数据加载mnist = mx.test_utils.get_mnist()batch_size = 100train_data = mx.io.NDArrayIter(mnist['train_data'], mnist['train_label'], batch_size, shuffle=True)val_data = mx.io.NDArrayIter(mnist['test_data'], mnist['test_label'], batch_size)# CNN模型class Net(gluon.Block):
def __init__(self, **kwargs):
super(Net, self).__init__(**kwargs)
self.conv1 = nn.Conv2D(20, kernel_size=(5,5))
self.pool1 = nn.MaxPool2D(pool_size=(2,2), strides = (2,2))
self.conv2 = nn.Conv2D(50, kernel_size=(5,5))
self.pool2 = nn.MaxPool2D(pool_size=(2,2), strides = (2,2))
self.fc1 = nn.Dense(500)
self.fc2 = nn.Dense(10)
def forward(self, x):
x = self.pool1(F.tanh(self.conv1(x)))
x = self.pool2(F.tanh(self.conv2(x)))
# 0 means copy over size from corresponding dimension.
# -1 means infer size from the rest of dimensions.
x = x.reshape((0, -1))
x = F.tanh(self.fc1(x))
x = F.tanh(self.fc2(x))
return x
net = Net()# 初始化与优化器定义# set the context on GPU is available otherwise CPUctx = [mx.gpu() if mx.test_utils.list_gpus() else mx.cpu()]net.initialize(mx.init.Xavier(magnitude=2.24), ctx=ctx)trainer = gluon.Trainer(net.collect_params(), 'sgd', {'learning_rate': 0.03})# 模型训练# Use Accuracy as the evaluation metric.metric = mx.metric.Accuracy()softmax_cross_entropy_loss = gluon.loss.SoftmaxCrossEntropyLoss()for i in range(epoch):
# Reset the train data iterator.
train_data.reset()
for batch in train_data:
data = gluon.utils.split_and_load(batch.data[0], ctx_list=ctx, batch_axis=0)
label = gluon.utils.split_and_load(batch.label[0], ctx_list=ctx, batch_axis=0)
outputs = []
# Inside training scope
with ag.record():
for x, y in zip(data, label):
z = net(x)
# Computes softmax cross entropy loss.
loss = softmax_cross_entropy_loss(z, y)
# Backpropogate the error for one iteration.
loss.backward()
outputs.append(z)
metric.update(label, outputs)
trainer.step(batch.data[0].shape[0])
# Gets the evaluation result.
name, acc = metric.get()
# Reset evaluation result to initial state.
metric.reset()
print('training acc at epoch %d: %s=%f'%(i, name, acc))26、 PaddlePaddle飞桨 # 导入需要的包import paddleimport numpy as npfrom paddle.nn import Conv2D, MaxPool2D, Linear## 组网import paddle.nn.functional as F# 定义 LeNet 网络结构class LeNet(paddle.nn.Layer):
def __init__(self, num_classes=1):
super(LeNet, self).__init__()
# 创建卷积和池化层
# 创建第1个卷积层
self.conv1 = Conv2D(in_channels=1, out_channels=6, kernel_size=5)
self.max_pool1 = MaxPool2D(kernel_size=2, stride=2)
# 尺寸的逻辑:池化层未改变通道数;当前通道数为6
# 创建第2个卷积层
self.conv2 = Conv2D(in_channels=6, out_channels=16, kernel_size=5)
self.max_pool2 = MaxPool2D(kernel_size=2, stride=2)
# 创建第3个卷积层
self.conv3 = Conv2D(in_channels=16, out_channels=120, kernel_size=4)
# 尺寸的逻辑:输入层将数据拉平[B,C,H,W] -> [B,C*H*W]
# 输入size是[28,28],经过三次卷积和两次池化之后,C*H*W等于120
self.fc1 = Linear(in_features=120, out_features=64)
# 创建全连接层,第一个全连接层的输出神经元个数为64, 第二个全连接层输出神经元个数为分类标签的类别数
self.fc2 = Linear(in_features=64, out_features=num_classes)
# 网络的前向计算过程
def forward(self, x):
x = self.conv1(x)
# 每个卷积层使用Sigmoid激活函数,后面跟着一个2x2的池化
x = F.sigmoid(x)
x = self.max_pool1(x)
x = F.sigmoid(x)
x = self.conv2(x)
x = self.max_pool2(x)
x = self.conv3(x)
# 尺寸的逻辑:输入层将数据拉平[B,C,H,W] -> [B,C*H*W]
x = paddle.reshape(x, [x.shape[0], -1])
x = self.fc1(x)
x = F.sigmoid(x)
x = self.fc2(x)
return x27、 CNTK
NDLNetworkBuilder=[
run=ndlLR
ndlLR=[
# sample and label dimensions
SDim=$dimension$
LDim=1
features=Input(SDim, 1)
labels=Input(LDim, 1)
# parameters to learn
B0 = Parameter(4)
W0 = Parameter(4, SDim)
B = Parameter(LDim)
W = Parameter(LDim, 4)
# operations
t0 = Times(W0, features)
z0 = Plus(t0, B0)
s0 = Sigmoid(z0)
t = Times(W, s0)
z = Plus(t, B)
s = Sigmoid(z)
LR = Logistic(labels, s)
EP = SquareError(labels, s)
# root nodes
FeatureNodes=(features)
LabelNodes=(labels)
CriteriaNodes=(LR)
EvalNodes=(EP)
OutputNodes=(s,t,z,s0,W0)
]
]总结与分类python 常用机器学习及深度学习库总结
分类可以根据其主要用途将这些库进行分类:
推荐学习:python视频教程 以上就是python常用机器学习及深度学习库介绍(总结分享)的详细内容,更多请关注模板之家(www.mb5.com.cn)其它相关文章! |






 有关更多
有关更多