基本数据类型,也称原始数据类型 byte,short,char,int,long,float,double,boolean 他们之间的比较,应用双等号(==),比较的是他们的值。
 java中==和equals和hashCode的区别 (更多面试题推荐:java面试题及答案) 1、==java中的数据类型,可分为两类:
public class testDay {
public static void main(String[] args) {
String s1 = new String("11");
String s2 = new String("11");
System.out.println(s1 == s2);
System.out.println(s1.equals(s2));
}
}结果是:
 s1和s2都分别存储的是相应对象的地址。所以如果用 s1== s2时,比较的是两个对象的地址值(即比较引用是否相同),为false。而调用equals方向的时候比较的是相应地址里面的值,所以值为true。这里就需要详细描述下equals()了。 2、equals()方法详解equals()方法是用来判断其他的对象是否和该对象相等。其再Object里面就有定义,所以任何一个对象都有equals()方法。区别在于是否重写了该方法。 先看下源码: public boolean equals(Object obj) { return (this == obj);
}很明显Object定义的是对两个对象的地址值进行的比较(即比较引用是否相同)。但是为什么String里面调用equals()却是比较的不是地址而是堆内存地址里面的值呢。这里就是个重点了,像String 、Math、Integer、Double等这些封装类在使用equals()方法时,已经覆盖了object类的equals()方法。看下String里面重写的equals(): public boolean equals(Object anObject) { if (this == anObject) { return true;
} if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length; if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0; while (n-- != 0) { if (v1[i] != v2[i]) return false;
i++;
} return true;
}
} return false;
}重写了之后就是这是进行的内容比较,而已经不再是之前地址的比较。依次类推Math、Integer、Double等这些类都是重写了equals()方法的,从而进行的是内容的比较。当然,基本类型是进行值的比较。 需要注意的是当equals()方法被override时,hashCode()也要被override。按照一般hashCode()方法的实现来说,相等的对象,它们的hashcode一定相等。为什么会这样,这里又要简单提一下hashcode了。 3、hashcode()浅谈明明是java中==和equals和hashCode的区别问题,怎么一下子又扯到hashcode()上面去了。你肯定很郁闷,好了,我打个简单的例子你就知道为什么==或者equals的时候会涉及到hashCode。 举例说明下:如果你想查找一个集合中是否包含某个对象,那么程序应该怎么写呢?不要用indexOf方法的话,就是从集合中去遍历然后比较是否想到。万一集合中有10000个元素呢,累屎了是吧。所以为了提高效率,哈希算法也就产生了。核心思想就是将集合分成若干个存储区域(可以看成一个个桶),每个对象可以计算出一个哈希码,可以根据哈希码分组,每组分别对应某个存储区域,这样一个对象根据它的哈希码就可以分到不同的存储区域(不同的区域)。 所以再比较元素的时候,实际上是先比较hashcode,如果相等了之后才去比较equal方法。 看下hashcode图解:  一个对象一般有key和value,可以根据key来计算它的hashCode值,再根据其hashCode值存储在不同的存储区域中,如上图。不同区域能存储多个值是因为会涉及到hash冲突的问题。简单如果两个不同对象的hashCode相同,这种现象称为hash冲突。简单来说就是hashCode相同但是equals不同的值。对于比较10000个元素就不需要遍历整个集合了,只需要计算要查找对象的key的hashCode,然后找到该hashCode对应的存储区域查找就over了。  大概可以知道,先通过hashcode来比较,如果hashcode相等,那么就用equals方法来比较两个对象是否相等。再重写了equals最好把hashCode也重写。其实这是一条规范,如果不这样做程序也可以执行,只不过会隐藏bug。一般一个类的对象如果会存储在HashTable,HashSet,HashMap等散列存储结构中,那么重写equals后最好也重写hashCode。 总结:
2. int、char、long 各占多少字节数byte 是 字节 bit 是 位 1 byte = 8 bit char在java中是2个字节,java采用unicode,2个字节来表示一个字符 short 2个字节 int 4个字节 long 8个字节 float 4个字节 double 8个字节 3. int和Integer的区别
延伸: 关于Integer和int的比较
Integer i = new Integer(100); Integer j = new Integer(100); System.out.print(i == j); //false
Integer i = new Integer(100); int j = 100; System.out.print(i == j); //true
Integer i = new Integer(100); Integer j = 100; System.out.print(i == j); //false
Integer i = 100; Integer j = 100; System.out.print(i == j); //true Integer i = 128; Integer j = 128; System.out.print(i == j); //false 对于第4条的原因: java在编译Integer i = 100 ;时,会翻译成为Integer i = Integer.valueOf(100);,而java API中对Integer类型的valueOf的定义如下: public static Integer valueOf(int i){
assert IntegerCache.high >= 127; if (i >= IntegerCache.low && i <= IntegerCache.high){ return IntegerCache.cache[i + (-IntegerCache.low)];
} return new Integer(i);
}java对于-128到127之间的数,会进行缓存,Integer i = 127时,会将127进行缓存,下次再写Integer j = 127时,就会直接从缓存中取,就不会new了 4. java多态的理解1.多态概述
注意:在使用多态后的父类引用变量调用方法时,会调用子类重写后的方法。
定义格式:父类类型 变量名=new 子类类型(); 2.多态中成员的特点
Fu f=new Zi(); System.out.println(f.num);//f是Fu中的值,只能取到父中的值
Fu f1=new Zi(); System.out.println(f1.show());//f1的门面类型是Fu,但实际类型是Zi,所以调用的是重写后的方法。 3.instanceof关键字作用:用来判断某个对象是否属于某种数据类型。 * 注意: 返回类型为布尔类型 使用案例: Fu f1=new Zi();
Fu f2=new Son();if(f1 instanceof Zi){
System.out.println("f1是Zi的类型");
}else{
System.out.println("f1是Son的类型");
}4.多态的转型多态的转型分为向上转型和向下转型两种
5.多态案例:例1: package day0524;
public class demo04 {
public static void main(String[] args) {
People p=new Stu();
p.eat();
//调用特有的方法
Stu s=(Stu)p;
s.study();
//((Stu) p).study();
}
}
class People{
public void eat(){
System.out.println("吃饭");
}
}
class Stu extends People{
@Override
public void eat(){
System.out.println("吃水煮肉片");
}
public void study(){
System.out.println("好好学习");
}
}
class Teachers extends People{
@Override
public void eat(){
System.out.println("吃樱桃");
}
public void teach(){
System.out.println("认真授课");
}
}答案:吃水煮肉片 好好学习 例2: 请问题目运行结果是什么? package day0524;
public class demo1 {
public static void main(String[] args) {
A a=new A();
a.show();
B b=new B();
b.show();
}
}
class A{
public void show(){
show2();
}
public void show2(){
System.out.println("A");
}
}
class B extends A{
public void show2(){
System.out.println("B");
}
}
class C extends B{
public void show(){
super.show();
}
public void show2(){
System.out.println("C");
}
}答案:A B 5. String、StringBuffer和StringBuilder区别1、长度是否可变
2、执行效率
3、应用场景
StringBuffer和StringBuilder区别 1、是否线程安全
2、应用场景
6. 什么是内部类?内部类的作用内部类的定义将一个类定义在另一个类里面或者一个方法里面,这样的类称为内部类。 内部类的作用:
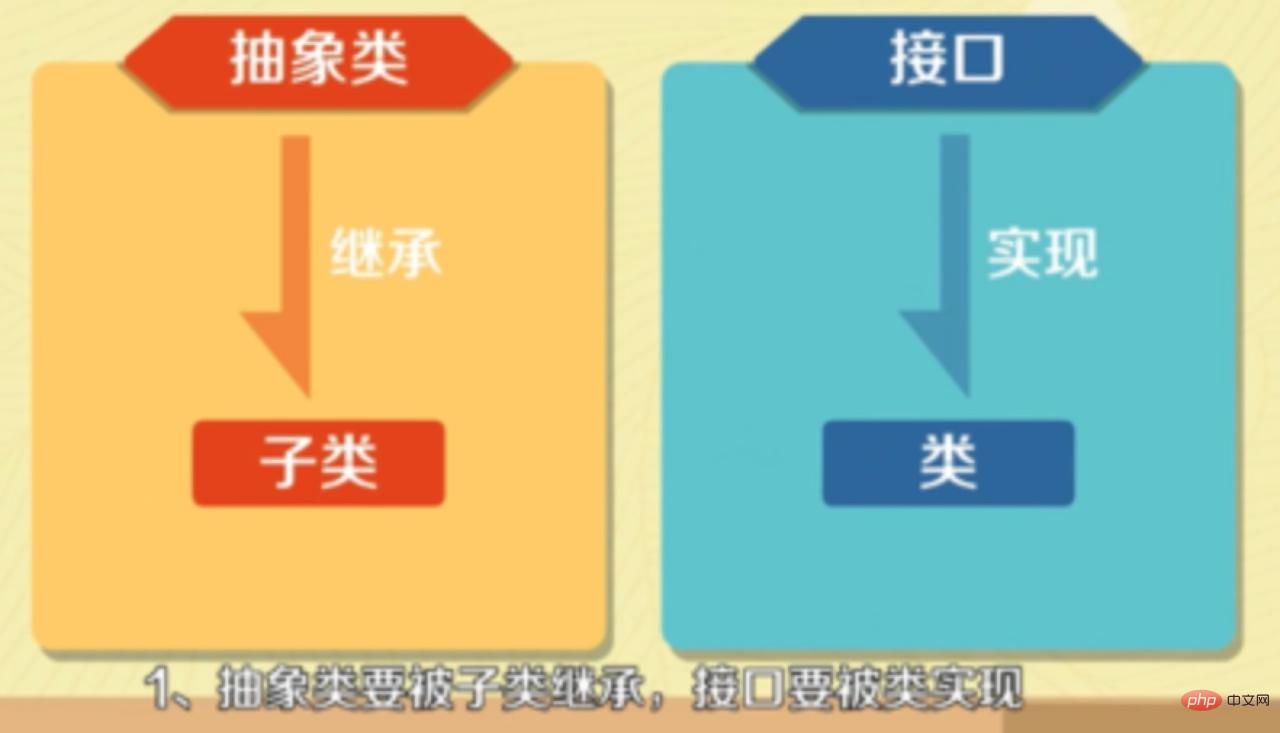
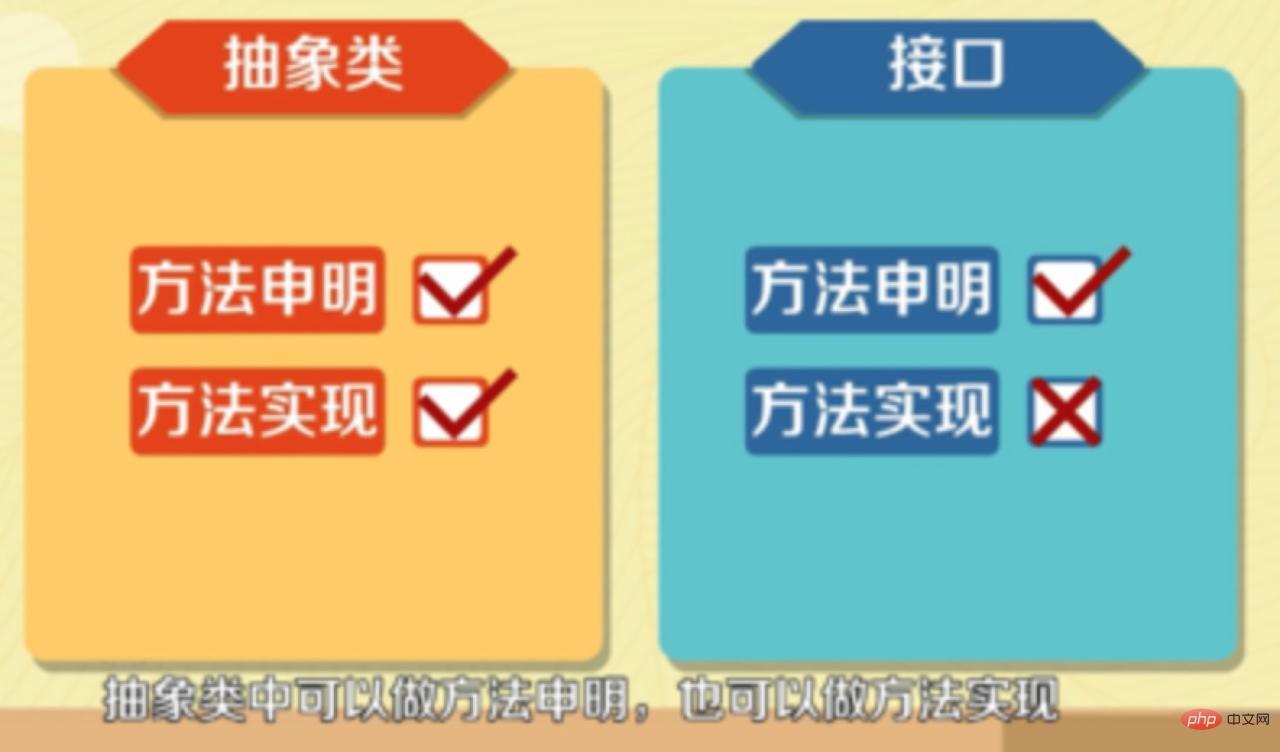
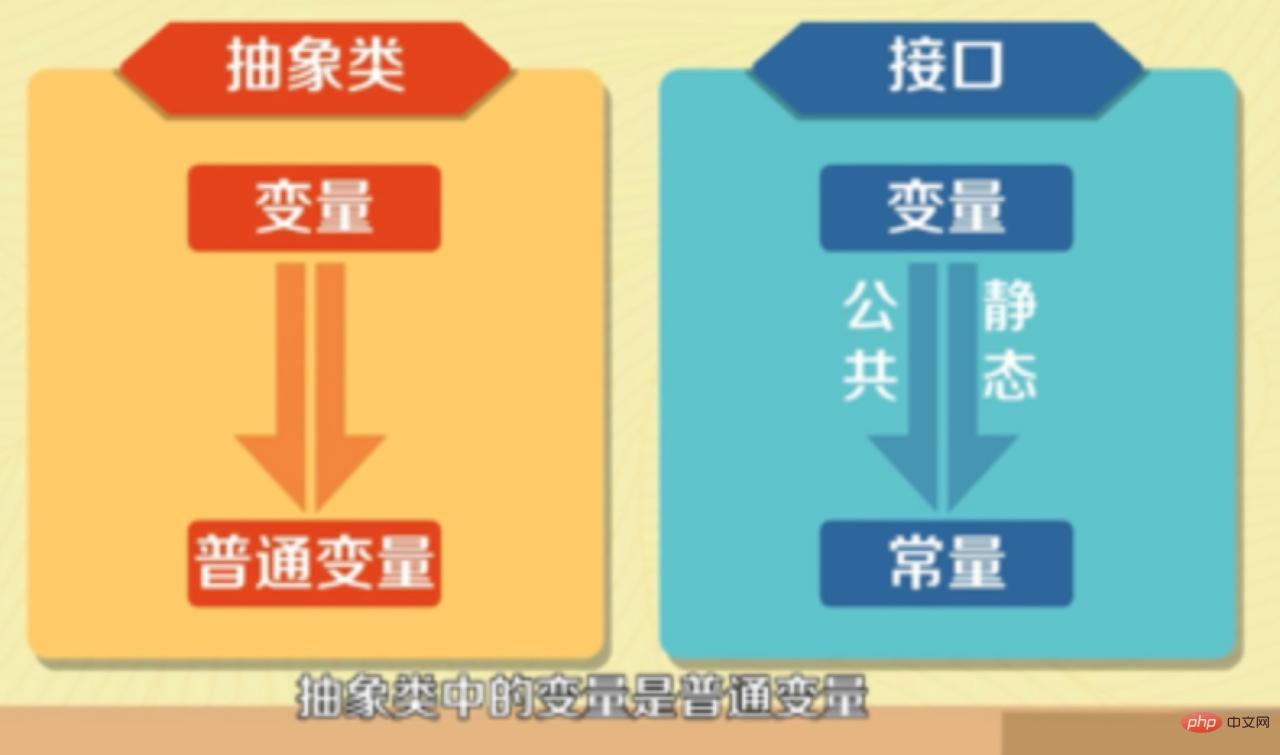
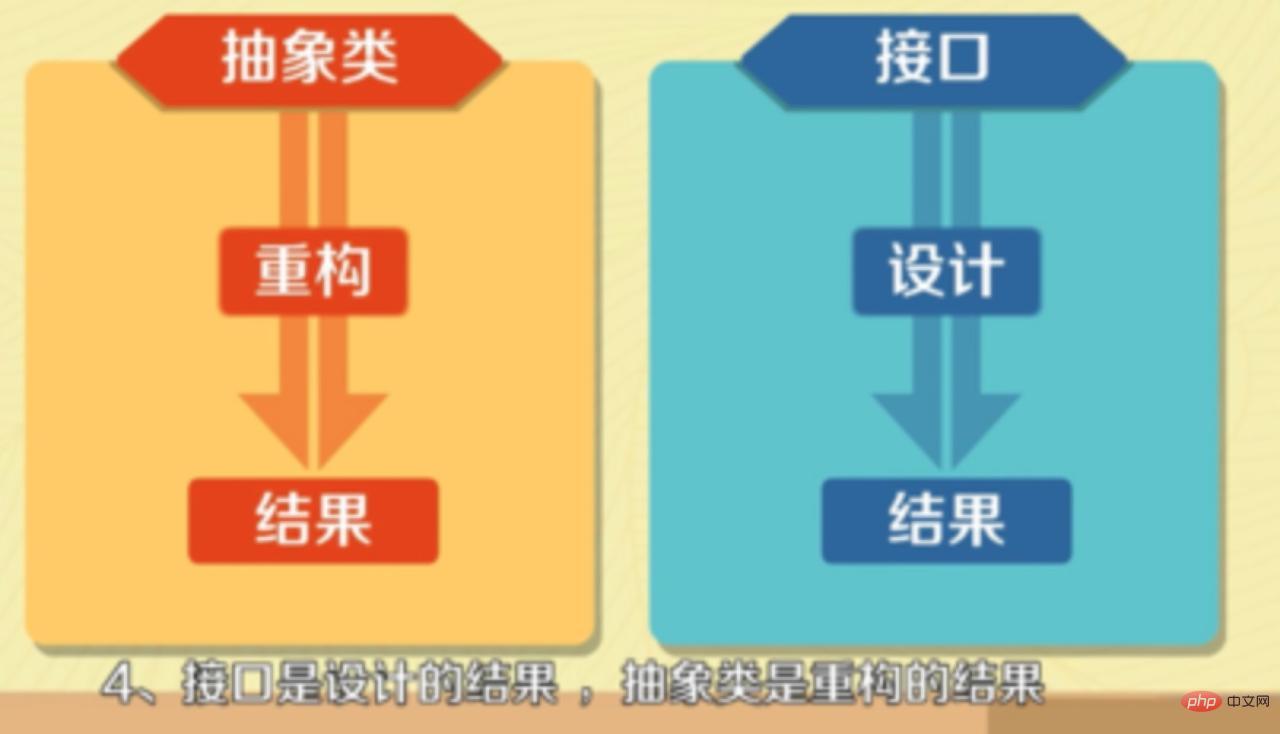
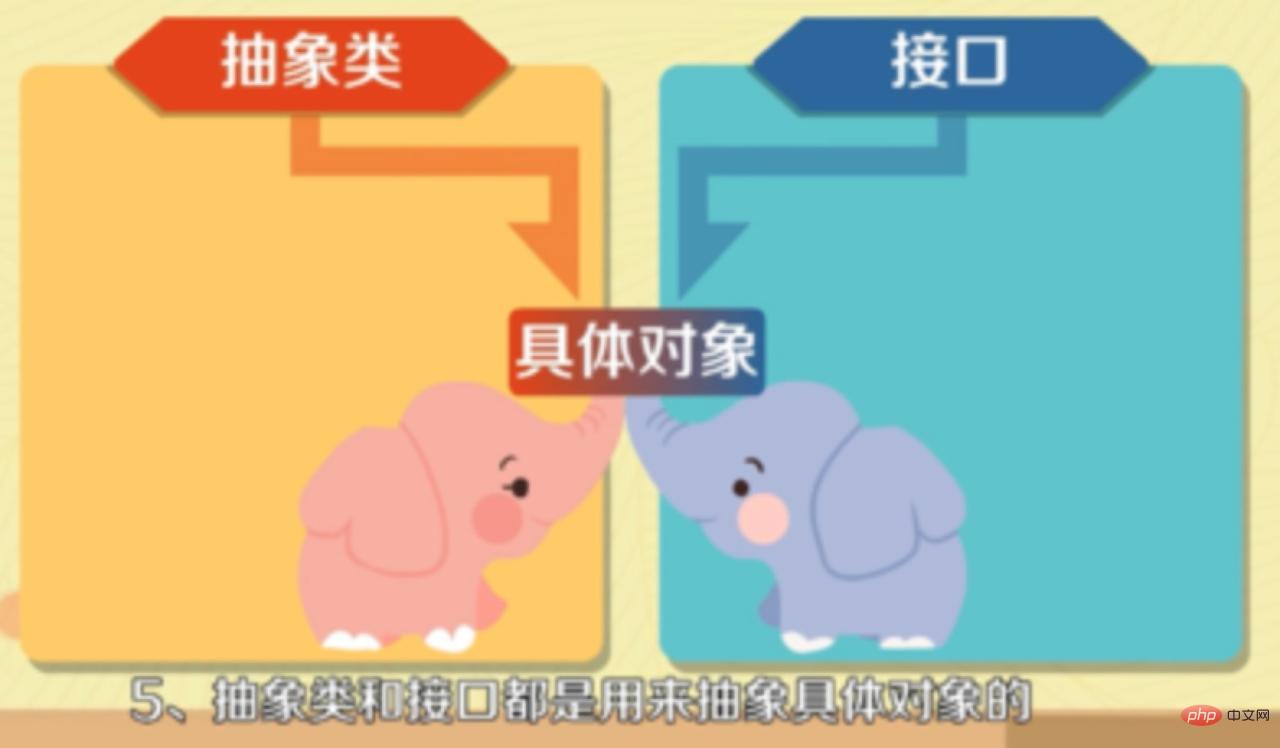
(学习视频推荐:java课程) 7. 抽象类和接口的区别
8. 抽象类的意义抽象类: 一个类中如果包含抽象方法,这个类应该用abstract关键字声明为抽象类。 意义:
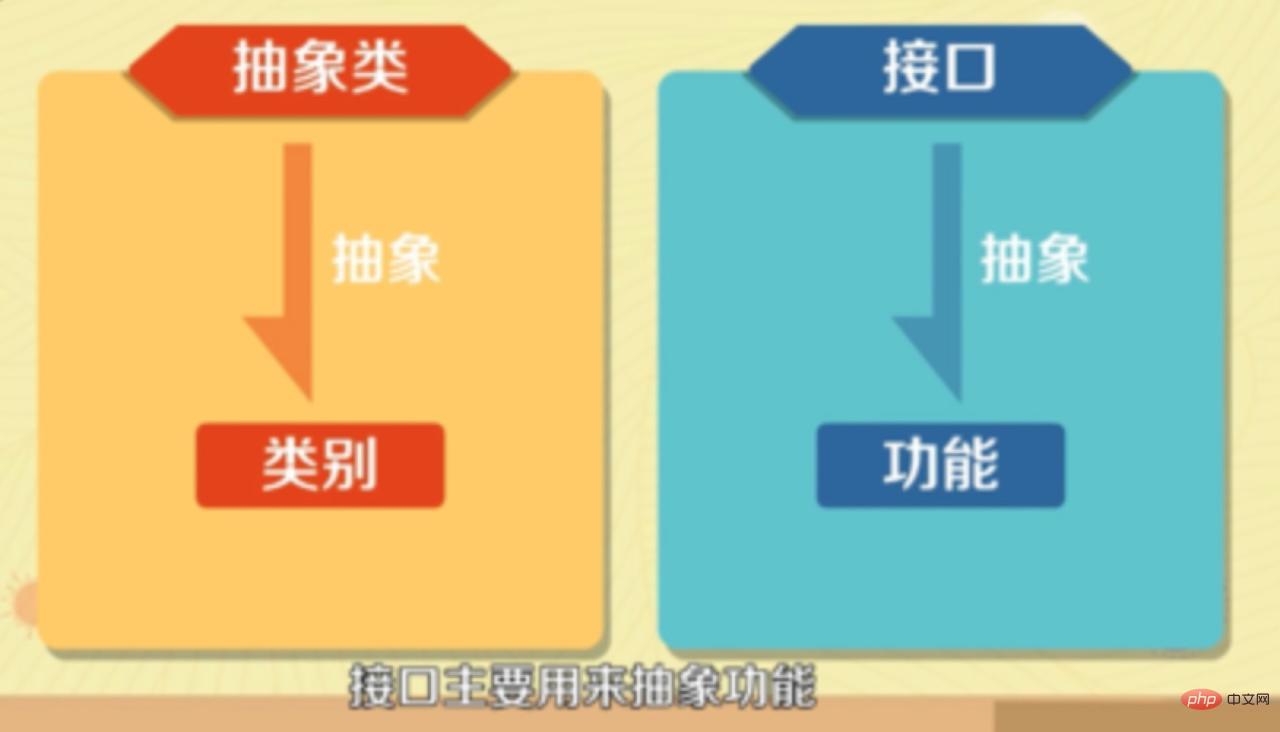
9. 抽象类与接口的应用场景1.接口(interface)的应用场合:
2.抽象类(abstract.class)的应用场合:一句话,在既需要统一的接口,又需要实例变量或缺省的方法的情况下,就可以使用它。最常见的有:
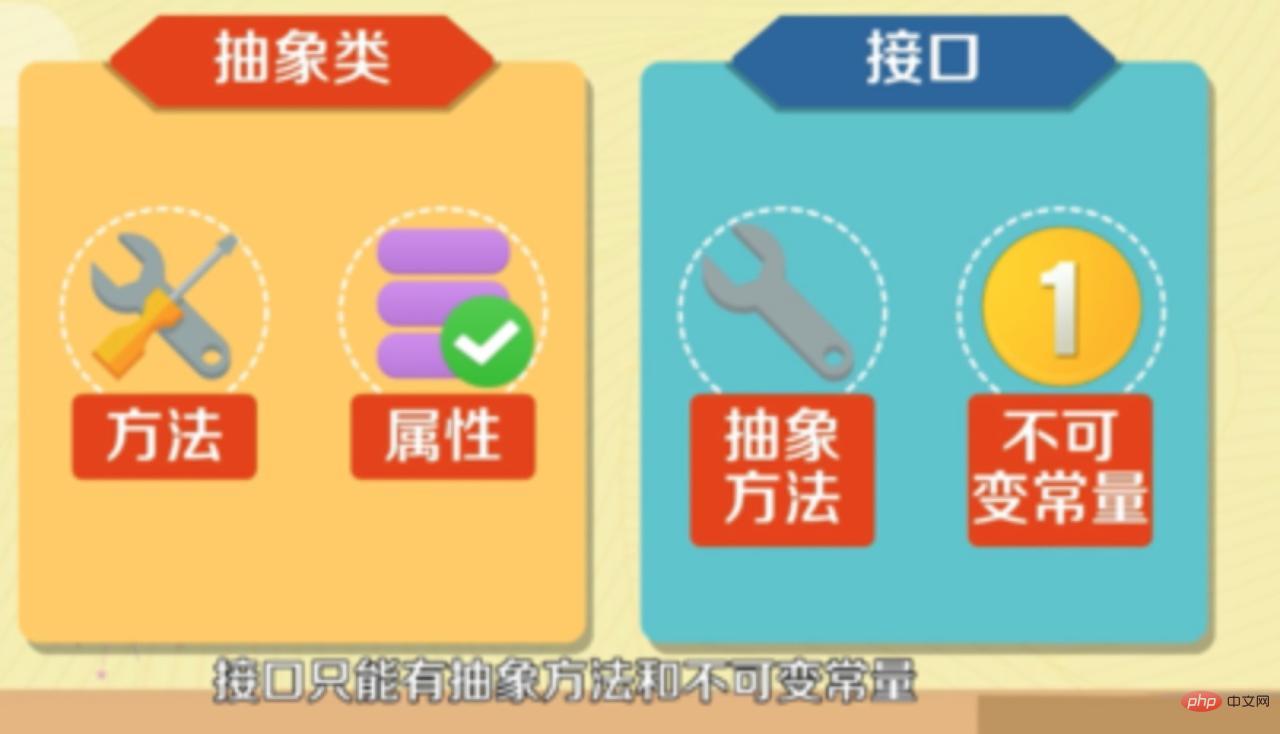
10. 抽象类是否可以没有方法和属性?答案是:可以 抽象类中可以没有抽象方法,但有抽象方法的一定是抽象类。所以,java中 抽象类里面可以没有抽象方法。注意即使是没有抽象方法和属性的抽象类,也不能被实例化。 11. 接口的意义
12. Java泛型中的extends和super理解在平时看源码的时候我们经常看到泛型,且经常会看到extends和super的使用,看过其他的文章里也有讲到上界通配符和下届通配符,总感觉讲的不够明白。这里备注一下,以免忘记。
这两点不难理解,extends修饰的只能取,不能放,这是为什么呢? 先看一个列子: public class Food {}
public class Fruit extends Food {}
public class Apple extends Fruit {}
public class Banana extends Fruit{}
public class GenericTest {
public void testExtends(List<? extends Fruit> list){
//报错,extends为上界通配符,只能取值,不能放.
//因为Fruit的子类不只有Apple还有Banana,这里不能确定具体的泛型到底是Apple还是Banana,所以放入任何一种类型都会报错
//list.add(new Apple());
//可以正常获取
Fruit fruit = list.get(1);
}
public void testSuper(List<? super Fruit> list){
//super为下界通配符,可以存放元素,但是也只能存放当前类或者子类的实例,以当前的例子来讲,
//无法确定Fruit的父类是否只有Food一个(Object是超级父类)
//因此放入Food的实例编译不通过
list.add(new Apple());
// list.add(new Food());
Object object = list.get(1);
}
}在testExtends方法中,因为泛型中用的是extends,在向list中存放元素的时候,我们并不能确定List中的元素的具体类型,即可能是Apple也可能是Banana。因此调用add方法时,不论传入new Apple()还是new Banana(),都会出现编译错误。 理解了extends之后,再看super就很容易理解了,即我们不能确定testSuper方法的参数中的泛型是Fruit的哪个父类,因此在调用get方法时只能返回Object类型。结合extends可见,在获取泛型元素时,使用extends获取到的是泛型中的上边界的类型(本例子中为Fruit),范围更小。 总结:在使用泛型时,存取元素时用super,获取元素时,用extends。 13. 父类的静态方法能否被子类重写不能,父类的静态方法能够被子类继承,但是不能够被子类重写,即使子类中的静态方法与父类中的静态方法完全一样,也是两个完全不同的方法。 class Fruit{
static String color = "五颜六色";
static public void call() {
System.out.println("这是一个水果");
}
}
public class Banana extends Fruit{
static String color = "黄色";
static public void call() {
System.out.println("这是一个香蕉");
}
public static void main(String[] args) {
Fruit fruit = new Banana();
System.out.println(fruit.color); //五颜六色
fruit.call(); //这是一个水果
}
}如代码所示,如果能够被重写,则输出的应该是这是一个香蕉。与此类似的是,静态变量也不能够被重写。如果想要调用父类的静态方法,应该使用类来调用。 那为什么会出现这种情况呢? 我们要从重写的定义来说:
对于静态方法和静态变量来说,虽然在上述代码中使用对象来进行调用,但是底层上还是使用父类来调用的,静态变量和静态方法在编译的时候就将其与类绑定在一起。既然它们在编译的时候就决定了调用的方法、变量,那就和重写没有关系了。 静态属性和静态方法是否可以被继承 可以被继承,如果子类中有相同的静态方法和静态变量,那么父类的方法以及变量就会被覆盖。要想调用就就必须使用父类来调用。 class Fruit{
static String color = "五颜六色";
static String xingzhuang = "奇形怪状";
static public void call() {
System.out.println("这是一个水果");
}
static public void test() {
System.out.println("这是没有被子类覆盖的方法");
}
}
public class Banana extends Fruit{
static String color = "黄色";
static public void call() {
System.out.println("这是一个香蕉");
}
public static void main(String[] args) {
Banana banana = new Banana();
banana.test(); //这是没有被子类覆盖的方法
banana.call(); //调用Banana类中的call方法 这是一个香蕉
Fruit.call(); //调用Fruit类中的方法 这是一个水果
System.out.println(banana.xingzhuang + " " + banana.color); //奇形怪状 黄色
}
}从上述代码可以看出,子类中覆盖了父类的静态方法的话,调用的是子类的方法,这个时候要是还想调用父类的静态方法,应该是用父类直接调用。如果子类没有覆盖,则调用的是父类的方法。静态变量与此相似。 14. 线程和进程的区别
可看下这篇文章:juejin.im/post/684490… 15. final,finally,finalize的区别
16. 序列化Serializable和Parcelable的区别Android中Intent如果要传递类对象,可以通过两种方式实现。
Serializable(Java自带):Serializable是序列化的意思,表示将一个对象转换成可存储或可传输的状态。序列化后的对象可以在网络上进行传输,也可以存储到本地。Serializable是一种标记接口,这意味着无需实现方法,Java便会对这个对象进行高效的序列化操作。 Parcelable(Android 专用):Android的Parcelable的设计初衷是因为Serializable效率过慢(使用反射),为了在程序内不同组件间以及不同Android程序间(AIDL)高效的传输数据而设计,这些数据仅在内存中存在。Parcelable方式的实现原理是将一个完整的对象进行分解,而分解后的每一部分都是Intent所支持的数据类型,这样也就实现传递对象的功能了。 效率及选择: Parcelable的性能比Serializable好,因为后者在反射过程频繁GC,所以在内存间数据传输时推荐使用Parcelable,如activity间传输数据。而Serializable可将数据持久化方便保存,所以在需要保存或网络传输数据时选择Serializable,因为android不同版本Parcelable可能不同,所以不推荐使用Parcelable进行数据持久化。 Parcelable不能使用在要将数据存储在磁盘上的情况,因为Parcelable不能很好的保证数据的持续性在外界有变化的情况下。尽管Serializable效率低点,但此时还是建议使用Serializable 。 通过intent传递复杂数据类型时必须先实现两个接口之一,对应方法分别是getSerializableExtra(),getParcelableExtra()。 17. 静态属性和静态方法是否可以被继承?是否可以被重写?以及原因?父类的静态属性和方法可以被子类继承 不可以被子类重写:当父类的引用指向子类时,使用对象调用静态方法或者静态变量,是调用的父类中的方法或者变量。并没有被子类改写。 原因: 因为静态方法从程序开始运行后就已经分配了内存,也就是说已经写死了。所有引用到该方法的对象(父类的对象也好子类的对象也好)所指向的都是同一块内存中的数据,也就是该静态方法。 子类中如果定义了相同名称的静态方法,并不会重写,而应该是在内存中又分配了一块给子类的静态方法,没有重写这一说。 18 .java中静态内部类的设计意图内部类内部类,即定义在一个类的内部的类。为什么有内部类呢? 我们知道,在java中类是单继承的,一个类只能继承另一个具体类或抽象类(可以实现多个接口)。这种设计的目的是因为在多继承中,当多个父类中有重复的属性或者方法时,子类的调用结果会含糊不清,因此用了单继承。 而使用内部类的原因是:每个内部类都能独立地继承一个(接口的)实现,所以无论外围类是否已经继承了某个(接口的)实现,对于内部类都没有影响。 在我们程序设计中有时候会存在一些使用接口很难解决的问题,这个时候我们可以利用内部类提供的、可以继承多个具体的或者抽象的类的能力来解决这些程序设计问题。可以这样说,接口只是解决了部分问题,而内部类使得多重继承的解决方案变得更加完整。 静态内部类说静态内部类之前,先了解下成员内部类(非静态的内部类)。 成员内部类 成员内部类也是最普通的内部类,它是外围类的一个成员,所以它可以无限制的访问外围类的所有成员属性和方法,尽管是private的,但是外围类要访问内部类的成员属性和方法则需要通过内部类实例来访问。 在成员内部类中要注意两点:
静态内部类 静态内部类与非静态内部类之间存在一个最大的区别:非静态内部类在编译完成之后会隐含地保存着一个引用,该引用是指向创建它的外围内,但是静态内部类却没有。 没有这个引用就意味着:
其它两种内部类:局部内部类和匿名内部类 局部内部类 局部内部类是嵌套在方法和作用域内的,对于这个类的使用主要是应用与解决比较复杂的问题,想创建一个类来辅助我们的解决方案,到那时又不希望这个类是公共可用的,所以就产生了局部内部类,局部内部类和成员内部类一样被编译,只是它的作用域发生了改变,它只能在该方法和属性中被使用,出了该方法和属性就会失效。 匿名内部类
相关推荐:java入门 以上就是2020全新java基础面试题汇总的详细内容,更多请关注模板之家(www.mb5.com.cn)其它相关文章! |